人为操纵图片?这回可能是编辑的错
近日,Elisabeth Bik 在某公共论坛指出,一篇发表于 2004 年的文章 [1] 可能存在“人为操纵图片”,若干张图片的右上角出现了重复的单元。

然而,在不到一个小时后事情出现了重大进展。论文通讯作者 Jürgen Götz 提供了保存于 20 多年前的原始图片。图片显示,在其右上角并没有文章中出现的重复单元。经过这一对比,基本上能确定,论文中所谓“人为操纵图片”的现象,实质上是期刊编辑在处理图片过程中所造成。
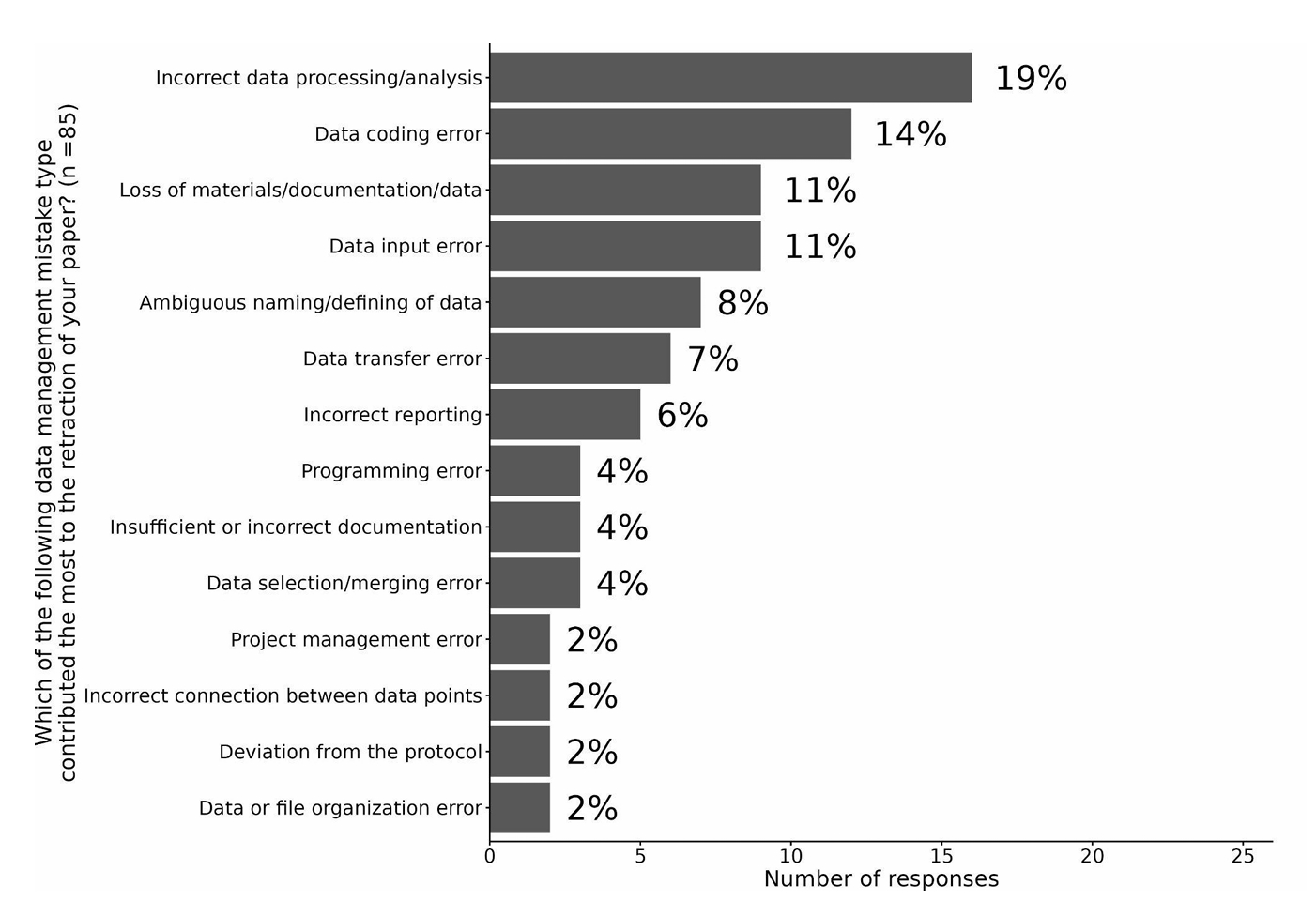
这一事件给我们展示了一个鲜见的现象,提醒我们期刊的编辑/生产部门职员在处理图片时需要更加谨慎,另外一方面,也提醒我们妥善管理原始数据/图标的重要性。
Reference